De la descripción de Wikipedia sobre las imágenes ráster:
En computación gráfica y fotografía digital, un gráfico rásterizado representa una imagen bidimensional como una matriz rectangular o rejilla de píxeles, que puede visualizarse mediante una pantalla de computadora, paper, o cualquier otro medio de visualización.
El término “dato ráster” o “ráster” proviene de los gráficos por computadora. En esencia, un ráster se refiere a una secuencia de valores numéricos dispuestos en una tabla rectangular (similar a una matriz de álgebra lineal).
Los conjuntos de datos ráster son útiles para representar cantidades continuas, como presión, elevación, temperatura, clasificación de la cobertura terrestre, etc., muestreadas en una teselación, es decir, una cuadrícula discreta que divide una región bidimensional de extensión finita. En el contexto de los Sistemas de Información Geográfica (GIS, por las siglas en inglés de, Geographic Information System), la región espacial es la proyección plana de una porción de la superficie terrestre.
Los rásters se aproximan a las distribuciones numéricas continuas almacenando valores individuales dentro de cada celda de la cuadrícula o píxel (un término derivado del “elemento de imagen” en los gráficos por computadora). Los rásters pueden representar datos recopilados en varios tipos de celdas de cuadrícula no rectangulares (por ejemplo, hexágonos). Para nuestros fines, restringiremos nuestra atención en las cuadrículas en las que todos los píxeles son rectángulos que tienen el mismo ancho y alto.

En esta imagen se muestra un ejemplo de datos ráster. Fuente: *National Ecological Observatory Network* (NEON)(en español, Red Nacional de Observatorios Ecológicos).
Cómo comprender los valores de los ráster¶
Una diferencia sutil e importante entre una matriz numérica conocida del álgebra lineal y un ráster en el contexto de los SIG es que los conjuntos de datos reales a menudo están incompletos. Es decir, un ráster puede carecer de entradas o puede incluir valores de píxeles que se corrompieron durante el proceso de medición. Por eso, la mayoría de los datos ráster incluyen un esquema para representar los valores “Sin datos” de los píxeles en los que no es posible hacer una observación significativa. El esquema puede utilizar “No es un número” (“NaN” , por las siglas en inglés de Not-a-Number) para los datos de punto flotante o un valor testigo para los datos enteros (por ejemplo, utilizando -1 para señalar los datos que faltan cuando los datos enteros significativos son estrictamente positivos).
Otra propiedad importante de los datos ráster es que los valores de los píxeles se almacenan utilizando un tipo de datos apropiado para el contexto. Por ejemplo, las funciones continuas, como la altitud o la temperatura, suelen almacenarse como datos ráster utilizando números de punto flotante. Por el contrario, las propiedades categóricas (como los tipos de cobertura del suelo) pueden almacenarse utilizando números enteros sin signo. Los conjuntos de datos ráster suelen ser grandes, así que elegir el tipo de datos siguiendo un criterio puede reducir significativamente el tamaño del archivo sin comprometer la calidad de la información. Veremos esto con ejemplos más adelante.
Comprensión del Píxel vs. Coordenadas continuas¶
Cada píxel de un ráster está indexado por su posición en la fila y columna con respecto a la esquina superior izquierda de la imagen o de las coodenadas del píxel. Estos valores representan el desplazamiento desde la esquina superior izquierda de la matriz, expresado convencionalmente utilizando una indexación desde cero (en inglés, zero based numbering). Por ejemplo, si se utiliza la indexación desde cero en la cuadrícula de píxeles 10\tveces10 que se muestra a continuación, el píxel de la esquina superior izquierda tendrá el índice (0,0), el píxel de la esquina superior derecha tendrá el índice (0,9), el píxel de la esquina inferior izquierda tendrá el índice (9,0), y el píxel de la esquina inferior derecha tendrá el índice (9,9).

(de http://ioam.github.io/topographica)
La indexación desde cero no se observa universalmente (por ejemplo, MATLAB utiliza la indexación basada en matrices y arreglos), así que debemos ser conscientes de cuál convención se utiliza en cualquier herramienta utilizada. Sin importar si vamos a contar filas/columnas desde uno o desde cero, cuando se utilizan coordenadas de píxel/imagen/matriz, convencionalmente, el índice de la fila aumenta desde la fila superior y aumenta al desplazarse hacia abajo.
Otra sutil distinción entre matrices y rásters es que los datos ráster suelen estar georreferenciados, esto significa que cada celda está asociada a un rectángulo geográfico concreto de la superficie terrestre con cierta área positiva. Esto a su vez significa que cada valor del píxel está asociado no solo con sus coordenadas de píxel/imagen, sino también con las coordenadas continuas de cada punto espacial dentro de ese rectángulo físico. Es decir, hay un continuo de coordenadas espaciales asociadas a cada píxel en contraposición a un único par de coordenadas del píxel. Por ejemplo, en la cuadrícula de píxeles que se muestra a continuación en el gráfico de la izquierda, el punto rojo asociado a las coordenadas del píxel se encuentra en el centro de ese píxel. Al mismo tiempo, el gráfico de la derecha muestra un punto rojo con coordenadas continuas .
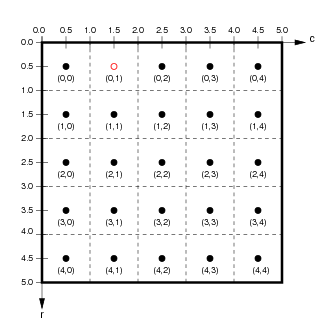
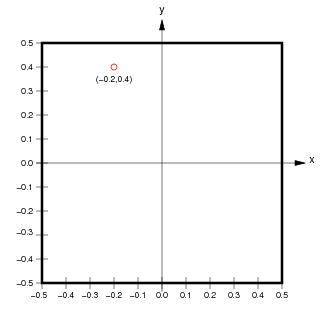
(from http://ioam.github.io/topographica)
Hay dos distinciones importantes que se deben observar:
- Las coordenadas de imagen se expresan normalmente en orden inverso a las coordenadas continuas. Es decir, para las coordenadas de imagen , la posición vertical, la fila , es la primera ordenada, y la posición horizontal, la columna , es la segunda ordenada. Por el contrario, cuando se expresa una posición en coordenadas continuas , convencionalmente, la posición horizontal es la primera ordenada y la posición vertical es la segunda ordenada.
- La orientación del eje vertical se invierte entre coordenadas de píxel y coordenadas continuas (aunque la orientación del eje horizontal es la misma). Es decir, el índice de fila aumenta hacia abajo desde la esquina superior izquierda en coordenadas del píxel, mientras que la coordenada vertical continua aumenta hacia arriba desde la esquina inferior izquierda.
Las convenciones contradictorias con la indexación basada en cero y el orden de las coordenadas son fuente de muchos problemas en programación. Por ejemplo, en la práctica, algunas herramientas SIG exigen que las coordenadas se proporcionen como (longitud, latitud) y otras como (latitud, longitud). Con suerte, los usuarios de SIG pueden confiar en que las herramientas de software manejen estas inconsistencias de forma transparente (consulta, por ejemplo, esta discusión en la documentación de Holoviz). Cuando los resultados calculados no tienen sentido, lo importante es preguntar siempre:
- qué convenciones se utilizan para representar los datos ráster que se recuperaron de una fuente determinada, y
- qué convenciones requiere cualquier herramienta SIG se utiliza para manipular datos ráster.
Conservación de los metadatos¶
Los datos ráster usualmente van acompañados de una variedad de metadatos. Estos pueden incluir:
- el Sistema de Referencia de Coordenadas (SRC)(en inglés, Coordinate Reference System, CRS): las posibles representaciones incluyen el registro EPSG, WKT, etc.
- el valor NoData: el/los valor(es) testigo/s que señalan datos ausentes/corruptos (por ejemplo,
-1para datos enteros o255para datos enteros de 8 bits sin signo, etc.). - la resolución espacial: el área (en unidades adecuadas) de cada píxel.
- los límites: es la extensión del rectángulo espacial georreferenciado por estos datos ráster.
- la fecha y hora de adquisición: la fecha de adquisición de los datos, que a menudo se especifica mediante el Tiempo Universal Coordinada (UTC, por sus siglas en iglés de Coordinated Universal Time).
Los distintos formatos de archivo utilizan diferentes estrategias para adjuntar metadatos a un determinado conjunto de datos ráster. Por ejemplo, los productos de datos NASA OPERA generalmente tienen nombres de archivo como:
OPERA_L3_DIST-ALERT-HLS_T10TEM_20220815T185931Z_20220817T153514Z_S2A_30_v0.1_VEG-ANOM-MAX.tifEste nombre incluye una marca de tiempo (20220815T185931Z) y una ubicación geográfica MGRS (10TEM). Este tipo de convenciones para la denominación de los archivos permite determinar los atributos de los datos ráster sin necesidad de recuperar todo el conjunto de datos, lo que puede reducir significativamente los costos de transferencia de los datos.
Uso de GeoTIFF¶
Hay numerosos formatos de archivo estándar que se utilizan para compartir muchos tipos de datos científicos (por ejemplo, HDF, Parquet, CSV, etc.). Además, hay docenas de formatos de archivo especializados para los *(Sistemas de Información Geográfica (GIS), por ejemplo, DRG, NetCDF, USGS DEM, DXF, DWG, SVG, etc. En este tutorial, nos enfocaremos exclusivamente en el uso del formato de archivo GeoTIFF para representar los datos ráster.
GeoTIFF es un estándar de metadatos de dominio público diseñado para trabajar con archivos Formato de archivo de imagen etiquetado ( (TIFF, por sus siglas en inglés de Tagged Image File Format))). El formato GeoTIFF permite incluir información de georreferenciación como metadatos geoespaciales dentro de los archivos de imagen. Las aplicaciones SIG utilizan GeoTIFF para fotografías aéreas, imágenes de satélite y mapas digitalizados. El formato de los datos GeoTIFF se describe detalladamente en el documento estándar OGC GeoTIFF.
Un archivo GeoTIFF usualmente incluye metadatos geográficos como etiquetas embebidas. Estos pueden incluir metadatos de imágenes ráster tales como:
- extensión espacial, es decir, el área que cubre el conjunto de datos,
- el SRC qué se utiliza para almacenar los datos,
- la resolución espacial, es decir, las dimensiones horizontal y vertical de los píxeles,
- el número de valores del píxel en cada dirección,
- el número de capas del archivo
.tif, - elipsoides y geoides (es decir, modelos estimados de la forma de la Tierra), y
- reglas matemáticas de proyección cartográfica para transformar los datos de un espacio tridimensional en una visualización bidimensional.
A modo de ejemplo, carguemos los datos de un archivo GeoTIFF local utilizando el paquete rioxarray de Python.
from pathlib import Path
import rioxarray as rio
FILE_STEM = Path.cwd().parent if 'book' == Path.cwd().parent.stem else 'book'
LOCAL_PATH = Path(FILE_STEM, 'assets/OPERA_L3_DIST-ALERT-HLS_T10TEM_20220815T185931Z_20220817T153514Z_S2A_30_v0.1_VEG-ANOM-MAX.tif')%%time
da = rio.open_rasterio(LOCAL_PATH)La función rioxarray.open_rasterio cargó los datos raster del archivo GeoTIFF local en un Xarray DataArray llamado da. Podemos analizar cómodamente el contenido de da en un cuaderno computacional Jupyter.
da # examine contentsEste ráster es de alta resolución ( píxeles). Vamos a tomar una parte más pequeña (por ejemplo, un muestreo cada 200 píxeles) creando una instancia del objeto slice de Python subset y usando el método Xarray DataArray.isel para construir una matriz de menor resolución (que se renderizará más rápido). Entonces podemos hacer una visualización (renderizado por Matplotlib de manera predeterminada).
subset = slice(0,None,200)
view = da.isel(x=subset, y=subset)
view.plot();Observe que la visualización se etiqueta utilizando las coordenadas continuas (este, norte) asociadas a la extensión espacial de este ráster. Es decir, la sutil contabilidad necesaria para hacer un seguimiento de las coordenadas continuas y de píxel fue administrada de forma transparente por la API de la estructura de datos. ¡Eso es bueno!